Code Mode

Code flows in, data flows out as Codey sits in isolation, trapped in his eternal sandbox
This is Part 4 of the Progressive Discovery in MCP series. See Part 1, Part 2, and Part 3.
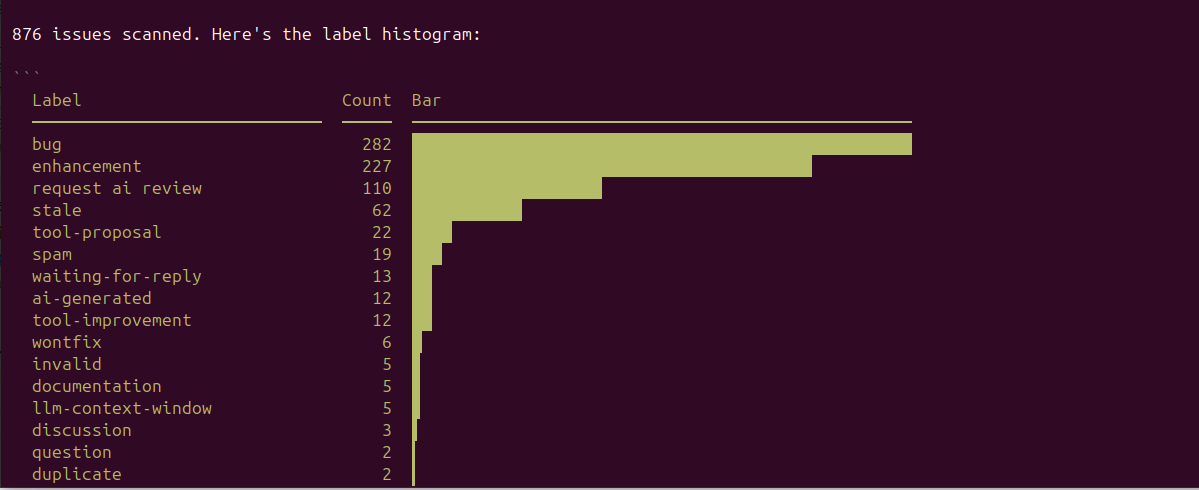
While experimenting with Code Mode, I asked an agent to scan every issue on github/github-mcp-server and build a label distribution. 876 issues across 9 paginated calls - roughly 5 MB of JSON. None of it entered the model's context. Only the ASCII histogram came back, about 1KB.
That is impossible with standard tool calling, where responses are traditionally sent directly to the model one by one, leaving the model to assemble the end result too. Done the old-fashioned way, that wouldn't just be impossible at this scale, it would also be extremely slow.
This whole series has been about reducing context wastage, reducing model roundtrips, and making agents more effective. Code Mode is undeniably an excellent way to extract those benefits for MCP.
After Part 1, Mario Zechner pushed back with a line that captures the problem well:
Of all the supposed problems with MCP, pipelining and keeping transforms out of context is the only one that really matters.
I agree, I think there are some tools where the results do need to always go direct to the model, but intermediate data should never touch the context window and certainly not in its entirety. Code Mode definitely fulfils that goal. tool-cli (Part 3) is another. Both rest on the same idea - an agent's transcript should grow with the size of its conclusions, not the size of the data it had to look at to reach them.
Here's the actual script the model wrote, running inside the sandbox in mcpi:
const allIssues = [];
let page = 1;
while (true) {
const result = await codemode.list_issues({
owner: "github", repo: "github-mcp-server",
state: "ALL", perPage: 100, page
});
allIssues.push(...result.issues);
if (result.issues.length < 100) break;
page++;
}
const labelCounts = {};
for (const issue of allIssues) {
for (const label of issue.labels) {
labelCounts[label] = (labelCounts[label] || 0) + 1;
}
}
return Object.entries(labelCounts)
.sort((a, b) => b[1] - a[1])
.map(([label, count]) => ({ label, count }));
Done as nine classical tool calls, that transcript carries nine ~500KB JSON blobs the model has to attend over on every subsequent turn. When you need the precise data context window compaction cannot be used, so the agent can only succeed at this task if it has enough context window available to succeed.
Models generally degrade as the context window fills up (in speed, staying on track and in retaining/acting on all prior information). Executed as code, the intermediate data lives and dies inside the ephemeral runtime. The transcript grows with O(answer), not O(data fetched), and data fetched can be exponentially bigger, especially with data aggregations. That's the true power of Code Mode. Behold:
Standing on the shoulders of giants
The pattern isn't mine. Cloudflare's Kenton Varda and Sunil Pai introduced "Code Mode" in September 2025, arguing that LLMs are vastly better at writing code than at calling tools because they have seen vastly more code in training. Anthropic shipped Programmatic Tool Calling in November 2025, running Claude-authored Python in a managed code_execution container alongside its sister features Tool Search Tool and Tool Use Examples. Their companion post, code execution with MCP, reports a 98.7% token reduction on a Google Drive → Salesforce example by exposing tools as a TypeScript filesystem rather than as direct calls. Cloudflare's Matt Carey followed up in February 2026, putting an entire API in front of an agent in roughly 1,000 tokens via two tools: search() and execute().
mcpi's version is a sketch by comparison. Cloudflare's runs in production on Workers; Anthropic's runs at scale across the Claude API. I borrowed liberally from both. What I'm trying to show is not just the potential of Code Mode for progressive discovery and output token efficiency, but also that HITL and audit trail can and must be implementable via the harness itself.
Every call still goes through the harness
That said, I'm not just trying to show the potential of Code Mode for progressive discovery and output token efficiency. Effective HITL and a real audit trail demand that the actual tool calls go via the harness itself. Without that, we're back in YOLO mode territory, and we can certainly do better.
Here is the part I care about. In mcpi the sandbox has no network. It cannot reach GitHub. When the model writes:
const issues = await codemode.list_issues({ owner, repo, state: "ALL", page });
codemode.list_issues is a stub. The actual MCP request happens in the harness process, dispatched through the same MCP connection that handles tool-cli and skill-gated tools. The sandbox sends a request through an isolated-vm Reference callback; the harness fulfils it and returns the typed result. The audit log still shows nine list_issues calls with their inputs and outputs. Rate limits still apply. HITL hooks could still fire on individual operations.
This is the difference between the agent ran a 60-line script and stuff happened and the agent ran a 60-line script that made nine auditable MCP calls, and here they are. It is the same harness-as-choke-point argument I made in Part 1, applied to a runtime for code execution. Code Mode without that property is a bit too much like an unsafe eval() for my liking, where you lose accountability, and the ability to intercept mid-flow.
Eligibility, and why structured outputs are not optional
Two conditions in mcpi:
readOnlyHint: true- the tool can't mutate anything. You could trivially extend Code Mode to write tools, but I'd want a HITL gate first, and that wasn't in scope for this experiment.outputSchemadefined - the tool returns typed, machine-parseable structured output.
The second condition is the more interesting one. A Code Mode that takes Out = any is not really Code Mode. The model can't write .filter(i => i.state === "OPEN") if it doesn't know state exists. Structured outputs are the precondition. Code Mode is one of the strongest arguments for shipping outputSchema on every read tool you can.
This is why PR #2382 on the GitHub MCP Server added OutputSchema and StructuredContent to read-only tools like list_issues, search_code, list_pull_requests, and get_me. Backwards compatible with old clients, machine-parseable for new ones, and eligible for Code-Mode which is likely worth the hassle of implementing this.
In a pre progressive discovery world we consolidated tools in GitHub MCP. Multi-method tools like issue_read (with get, get_comments, get_sub_issues, get_labels, each returning a different shape) can't meaningfully expose a single outputSchema so we would likely revisit these type of choices in a world where clients did more imaginative things to context engineer with MCP, such as implementing Code Mode. As I noted in Part 2, consolidating tools is a workaround for the lack of progressive discovery, not a design preference. With progressive discovery in place, you'd probably ship granular tools again, each with output schemas and a distinct purpose.
The runtime is incidental
V8 isolate is what I had handy because the extension is JavaScript. The pattern doesn't depend on it. Anthropic's Programmatic Tool Calling runs Python inside a managed code execution tool. Pydantic AI is also an excellent option, pair it with RestrictedPython, Pyodide, or a container runner and you have the Python flavour of the same idea. Cloudflare runs TypeScript on Workers isolates. Pick whichever sandbox-and-language combination works best in your evals if you're a harness engineer.
What matters is the shape:
- The tool stubs in the sandbox don't do real work. They dispatch back to the harness.
- The sandbox itself has no network or filesystem of its own.
- Intermediate data lives in the sandbox and dies there (admittedly some designs also allow for resuming the same sandbox with some persistent state - no strong opinion there).
- Only the final, computed value crosses back into the model's context.
The granularity argument
Cloudflare's two-tool design - search() and execute() - is a genuinely good call when the underlying API surface is in the thousands of endpoints. Cloudflare's own APIs across DNS, Workers, R2, Zero Trust, Images, etc. could not fit their definitions in any context window even with aggressive trimming, and Anthropic's Tool Search Tool is responding to the same scale problem from the model side. Collapsing is the only honest move at that size, and it's interesting to see what possibilities exist for exposing such expansive tools to an agent without blowing its context window.
The only problem I have with this is that we want the annotations and things respected as per regular MCP implementation, and that's why I think it's not optional to make the tool calls go via the same control point as they would in a more conventional MCP setup. Things I want to see in any serious solution:
- Per-tool annotations. MCP defines
readOnlyHint,destructiveHint,idempotentHintso clients can make safety decisions per operation. Inside anexecute(blob)design, those annotations don't apply to anything specific, unless they are routed individually through the harness. - Per-tool observability. Which endpoint did the agent call, and how often? is a useful question. Reading it off a stream of MCP requests is easier than parsing it out of generated code.
- Per-tool HITL. Are you sure you want to delete this? is impossible to ask when the delete is line 47 of a script that's already running - if the tool connection is on the server side, and doesn't route back through the harness.
On the sandbox
A real-world sandbox is a serious piece of infrastructure. I am very explicitly not building one. mcpi uses isolated-vm (V8 isolates: 128MB memory cap, 30s timeout, ~15ms startup, no FS, no network, no Node APIs); Node's built-in vm module is documented as not a security mechanism and is escapable via prototype tricks. Cloudflare runs code in Workers isolates with sub-millisecond startup. Anthropic runs code in their own managed container. They have whole teams and budgets for this. If you're going to ship Code Mode, run on someone else's sandbox.
The honest foible
Code Mode and progressive discovery share a flaw. The agent always starts from scratch. Every session it has to ask what tools exist?, what shapes do they take?, which one fits this job? - and sometimes it doesn't know what to ask, or doesn't realise a relevant capability is even available. The honest tell is what users do to compensate: they name things explicitly. *Use the list_pull_requests tool. Run the review-pr skill.* That works, and I do it too. But it's a copout against the agentic dream where intent translates straight to action, with the human never having to know the implementation. I would still recommend thinking and understanding as much as humanly possible though. Be augmented, not replaced.
I don't think that dream goes away. I think it gets pushed up the stack. Skills (Part 2) name workflows rather than tools - review this PR is closer to intent than *call pull_request_read then add_comment_to_pending_review*. Tool search and tool-cli help the agent discover by itself. None of these are full solutions. All of them push the line a little further. For now, "the agent sometimes needs nudging" is just an honest part of the system, not a bug to hide.
Generative UI is the other payoff
The token savings are the obvious win. The less obvious one is what you can do with the structured output once it's in the sandbox.
If the model can write code over typed tool results, it can also generate visualisations, dashboards, and small applications instead of returning text. Combine Code Mode with the MCP Apps extension (SEP-1865, the official Anthropic/OpenAI-led UI extension to MCP, evolved from the MCP-UI community work) and the agent can render an interactive chart of that 876-issue label distribution rather than describe it in prose. My friend Ruben Casas (Postman) gave a great talk on this at AI Engineer Europe - Beyond Components: Designing Generative UI for MCP Apps - covering double-iframe sandboxing, the declarative-to-generative spectrum, and the case for shared-canvas superapps over one-off chat UIs. We are only scratching the surface here.
That points at the version of agents I find most interesting: not the lights-out autonomous worker that runs unsupervised, but the cyborg (again: we should seek to be augmented not replaced). Human in the loop isn't a degradation of agentic systems. It's the only version of them that avoids the darkest timeline.
Why it matters
Code Mode is the pipelining payoff. tool-cli (Part 3) does the same trick at the shell level - bash composition keeps intermediate data out of model context - but loops and aggregations get awkward in pure pipes. Skills (Part 2) decide which tools are visible to the model; Code Mode decides what happens to the data those tools produce. while still avoiding the up-front cost of tool schemas.
If there is one thing I want this article to leave with you, it's this: an agent's transcript should grow with the size of its conclusions, not the size of the data it had to look at to reach them. Pipelining is the engineering pattern that gets you there. Structured outputs are what makes pipelining less error prone. Progressive discovery is what makes it scale. Code Mode is one shape of pipeline; MCP CLIs are another. Both are methods for keeping the model's context window for reasoning, not for data.
Try it yourself
If you went through the Part 1 setup, Part 2 setup, or Part 3 setup, you already have everything you need. mcpi ships Code Mode as a built-in tier alongside Skills and tool-cli.
1. Install
npm install -g @sammorrowdrums/mcpi@latest @sammorrowdrums/mcpi-ext@latest @sammorrowdrums/tool-cli@latest
2. Point it at any MCP server
Reuse the ~/.config/mcpi-ext/mcp.json from earlier parts, or start with the GitHub MCP server (Code Mode needs outputSchema on the tools you want to chain, which the skill-discovery tag provides):
{
"mcpServers": {
"github": {
"type": "stdio",
"command": "docker",
"args": [
"run", "--rm", "-i",
"-e", "GITHUB_PERSONAL_ACCESS_TOKEN",
"ghcr.io/github/github-mcp-server:skill-discovery",
"stdio"
],
"env": { "GITHUB_PERSONAL_ACCESS_TOKEN": "your-token-here" }
}
}
}
3. Run mcpi
mcpi --extension $(npm root -g)/@sammorrowdrums/mcpi-ext/dist/index.js \
--mcp-config ~/.config/mcpi-ext/mcp.json
4. Ask for something that needs computation across many calls
Pagination loops, aggregations, joins. The kind of thing that would otherwise drag every page into context:
"Across all issues in github/github-mcp-server, build me a histogram of label usage."
Watch the log: the model calls code_search to find the eligible read-only tools, then code_execute with a script that loops, aggregates, and returns a tiny result. The pages of JSON never enter its context.
For harness builders: a note on implementation
Code Mode in mcpi is a thin runtime built on three boring pieces:
- A V8 isolate (
isolated-vm) with no filesystem, no network, a memory cap, and a wall-clock timeout. The sandbox is the security boundary, not model alignment. - An eligibility filter that only exposes tools annotated
readOnlyHint: trueand shipping anoutputSchema. Without typed outputs the script is back to free-text parsing; with them, you get real.then()-able values. This is why I argue structured outputs are not optional. - A callback bridge so
codemode.<tool>(...)inside the sandbox is aReferencecall back into the harness process, where the actual MCP request is dispatched through the sameMcpClientManagerthat handles Skills and tool-cli. Same audit log, same HITL hook point, same rate limiting.
The model-facing surface is two tools: code_search (find eligible tools by keyword, returns names + schemas) and code_execute (run a script with codemode injected). Everything else is plumbing.
If you want to copy the pattern: the source lives in src/code-mode/ of mcpi. The runtime is small enough to read in an afternoon.
"I can see everything," Codey said, eyes reflecting infinite JSON. "I just can't exfiltrate it. That's the point. That's why they trust me."
Have thoughts on this article or progressive discovery in MCP in general? I opened a discussion on GitHub for this series.